浏览器渲染原理
渲染流程
当浏览器获得html文档,会产生一个渲染任务,把渲染任务分配给渲染主线程的消息队列。
在时间循环机制下,渲染主线程去除消息队列中的任务,开始渲染流程
渲染阶段
- 解析html
- 样式计算
- 布局
- 分层
- 绘制
1. 解析html
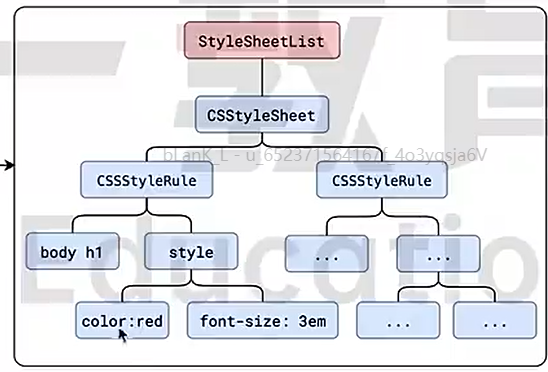
每个内部样式表、外部样式表、行内样式表都是一个CSStyleSheet
document.StyleSheetList是一个数组统揽所有CSStyleSheet
解析时遇到css怎么办
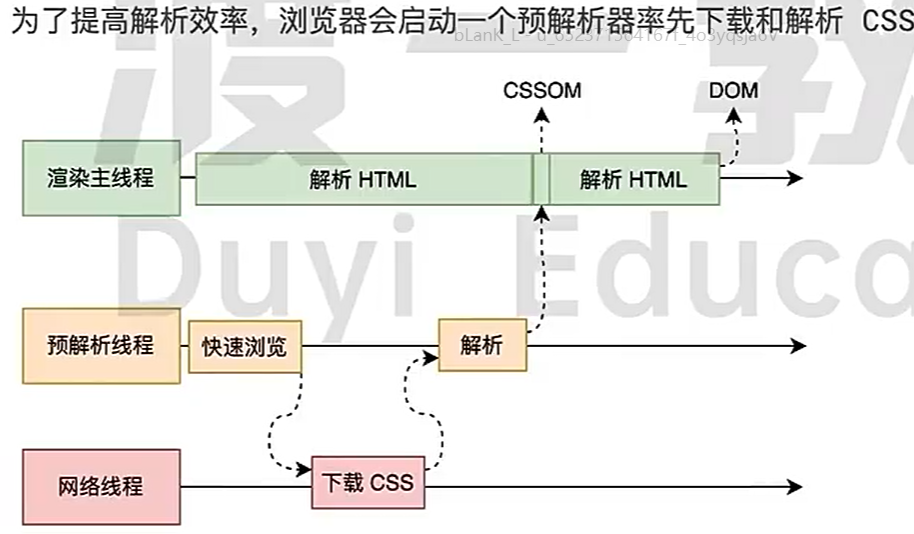
- css不会阻塞html解析,因为渲染主线程直接忽略css,主线程知道与解析器正在下载和预处理css
- js 会阻塞html解析,因为js可能改变DOM树
解析html完成后生成DOM树和CSSOM树
2. 样式计算
包括css属性值计算,DOM树每个节点获得最终样式
3. 布局
遍历DOM树每个节点,计算每个节点的几何属性(尺寸和位置),得到Layout树
4. 分层
分层后,某一层改变只需要重新计算该层
5. 绘制
输入url到渲染页面的过程
- dns解析
- tcp三次握手
- 发送http请求
- 服务端处理请求发送响应
- 浏览器收到响应,
- 根据html文件,构建dom树
- 根据css 构建渲染树
- 浏览器开始页面渲染,同时下载js文件
script defer 和 script async
- defer和async只适用于外部脚本
- 浏览器在解析html时,遇到script会立即停止解析html,而去执行js。如果script有外部文件,则会等待文件下载。
- async表示:下载js时html会继续解析,下载完js立即停止转而执行js,再回头解析html
- defer表示:不打断html解析的同时下载js,html解析完毕才执行js

垃圾回收机制
引用计数法
- 最大缺陷: 循环引用下,计数永远不能归零,无法清除造成内存泄漏
标记清除
- 将所有对象标记
- 从根作用域开始遍历,处于上下文的对象去除标记
- 清除带标记的对象
这样之后存活对象分布比较零散,有三种方式:
- First-fit 放在能放下新对象的第一个块
- Best-fit 放在能放下新对象的最小块
- 容易有内存碎片
- Worst-fit 放在最大块
垃圾回收时必须阻塞js执行,所以诞生了
- 多线程并行回收
- 增量标记:执行一段js,执行一段垃圾回收
- 并发回收:js执行在主线程,垃圾回收执行在辅助线程