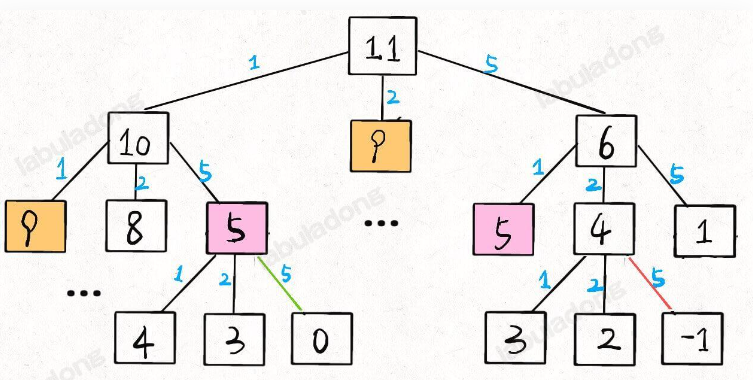
思想 大部分算法可以看作对于二叉树的操作
二叉树解题的思维模式分两类:
1、是否可以通过遍历一遍二叉树得到答案 ?如果可以,用一个 traverse 函数配合外部变量来实现,这叫「遍历」的思维模式。
2、是否可以定义一个递归函数,通过子问题(子树)的答案推导出原问题的答案 ?如果可以,写出这个递归函数的定义,并充分利用这个函数的返回值,这叫「分解问题」的思维模式。
无论使用哪种思维模式,你都需要思考:
如果单独抽出一个二叉树节点,它需要做什么事情?需要在什么时候(前/中/后序位置)做 ?其他的节点不用你操心,递归函数会帮你在所有节点上执行相同的操作。
1 2 3 4 5 6 7 8 9 void sort (int [] nums, int lo, int hi) { int p = partition(nums, lo, hi); sort(nums, lo, p - 1 ); sort(nums, p + 1 , hi); }
1 2 3 4 5 6 7 8 9 10 11 12 void sort (int [] nums, int lo, int hi) { int mid = (lo + hi) / 2 ; sort(nums, lo, mid); sort(nums, mid + 1 , hi); merge(nums, lo, mid, hi); }
前中后序是遍历二叉树过程中处理每一个节点的三个特殊时间点
前序位置的代码在刚刚进入一个二叉树节点的时候执行;
后序位置的代码在将要离开一个二叉树节点的时候执行;
中序位置的代码在一个二叉树节点左子树都遍历完,即将开始遍历右子树的时候执行。
两大框架 回溯框架【遍历】 DFS DFS 的关注点在单个 节点
1 2 3 4 5 6 7 8 9 10 11 void dfs (Node root) { if (root == null ) return ; print("我已经进入节点 %s 啦" , root) for (Node child : root.children) { dfs(child); } print("我将要离开节点 %s 啦" , root) }
回溯 回溯算法的关注点在节点间的 树枝
1 2 3 4 5 6 7 8 9 10 11 void backtrack (Node root) { if (root == null ) return ; for (Node child : root.children) { print("我站在节点 %s 到节点 %s 的树枝上" , root, child) backtrack(child); print("我将要离开节点 %s 到节点 %s 的树枝上" , child, root) } }
站在一个节点上我们需要考虑三个问题:
路径:也就是已经做出的选择。
选择列表:也就是你当前可以做的选择。
结束条件:也就是到达决策树底层,无法再做选择的条件。
排列组合 分为三种情况:
元素无重不可复选 (基础)
1 2 3 4 5 6 7 8 9 10 11 const backtrack = (start ) => { result.push ([...onPath]); for (let i = start; i < nums.length ; i++) { onPath.push (nums[i]); backtrack (i + 1 ); onPath.pop (); } };
不可复选,则start代表从索引start开始选,无需考虑前面的因为已经选过了。
元素可重不可复选
1 2 3 4 5 6 7 8 9 10 11 12 13 14 nums.sort ((a,b )=> a-b); const backtrack = (start=0 ) => { result.push ([...onPath]); for (let i = start; i < nums.length ; i++) { if (i>start && nums[i]==nums[i-1 ]) continue ; onPath.push (nums[i]); backtrack (i + 1 ); onPath.pop (); } };
因为元素可重但是选择不可重,所以需要剪枝。 先给nums排序,方便后面剪枝
元素无重可复选
1 2 3 4 5 6 7 8 9 10 11 12 13 14 nums.sort ((a,b )=> a-b); const backtrack = (start=0 ) => { result.push ([...onPath]); for (let i = start; i < nums.length ; i++) { onPath.push (nums[i]); backtrack (i); onPath.pop (); } };
BFS 层序遍历属于迭代遍历
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void levelTraverse (TreeNode root) { if (root == null ) return ; Queue<TreeNode> q = new LinkedList <>(); q.offer(root); let depth = 0 ; while (!q.isEmpty()) { int sz = q.size(); for (int i = 0 ; i < sz; i++) { TreeNode cur = q.poll(); if (cur.left != null ) { q.offer(cur.left); } if (cur.right != null ) { q.offer(cur.right); } } depth ++ ; } }
变形递归 二叉当作三叉 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 function traverse (node1, node2 ) { if (node1 === null || node2 === null ) { return ; } node1.next = node2; traverse (node1.left , node1.right ); traverse (node2.left , node2.right ); traverse (node1.right , node2.left ); }
从右向左的中序-倒序二叉搜索树 1 2 3 4 5 6 7 8 9 var traverse = function (root ) { if (root == null ) return ; traverse (root.right ); console .log (root.val ); traverse (root.left ); }
动规框架【分解】 1 2 3 4 5 6 def dp (状态1 , 状态2 , ... ): for 选择 in 所有可能的选择: result = 求最值(result, dp(状态1 , 状态2 , ...)) return result
1 2 3 4 5 6 7 8 dp[0 ][0 ][...] = base case for 状态1 in 状态1 的所有取值: for 状态2 in 状态2 的所有取值: for ... dp[状态1 ][状态2 ][...] = 求最值(选择1 ,选择2. ..)
动态规划问题必须符合 最优子结构
例如换零钱: 面值分别为 1,2,5,用最少硬币凑到总金额 amount = 11
子结构就是 凑到 10, 9, 6 的硬币数+12
子问题必须独立
因为每种硬币无限多,即凑到10元的结果,不影响凑到9元的结果
总结
对于动态规划的题目, 题目求什么,dp[i][j] 的值就代表什么。
DP树
压缩 如果计算状态 dp[i][j] 需要的都是 dp[i][j] 相邻的状态,那么就可以使用空间压缩技巧
链表
反转链表 递归方式
输入一个节点 head,将「以 head 为起点」的链表反转,并返回反转之后的头结点 。
1 2 3 4 5 6 7 8 9 ListNode reverse (ListNode head) { if (head == null || head.next == null ) { return head; } ListNode last = reverse(head.next); head.next.next = head; head.next = null ; return last; }
大根堆 求 n 个数字中的最大值
由数组构成的完全二叉树
两个功能: 插入和弹出
插入: 插入队尾,队尾冒泡
弹出: 队头和队尾交换,弹出队尾,队头下沉
所有操作都在头尾
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 public class MaxPQ <Key extends Comparable <Key>> { private Key[] pq; private int size = 0 ; public MaxPQ (int cap) { pq = (Key[]) new Comparable [cap + 1 ]; } public Key max () { return pq[1 ]; } public void insert (Key e) {...} public Key delMax () {...} private void swim (int x) { while (x > 1 && less(parent(x), x)) { swap(parent(x), x); x = parent(x); } } private void sink (int x) { while (left(x) <= size) { int max = left(x); if (right(x) <= size && less(max, right(x))) max = right(x); if (less(max, x)) break ; swap(x, max); x = max; } } private void swap (int i, int j) {...} private boolean less (int i, int j) { return pq[i].compareTo(pq[j]) < 0 ; } }
注意 js 除法不会自动取整
倒数第 k 个
双指针
p1 走出 k 步之后, p1 和 p2 再同步移动
只用遍历一次链表
链表-环
双指针
p1 走一步,p2 走两步, while 循环
如果 p2 === null, 说明没有环
如果 p2 === p1 , 说明有环
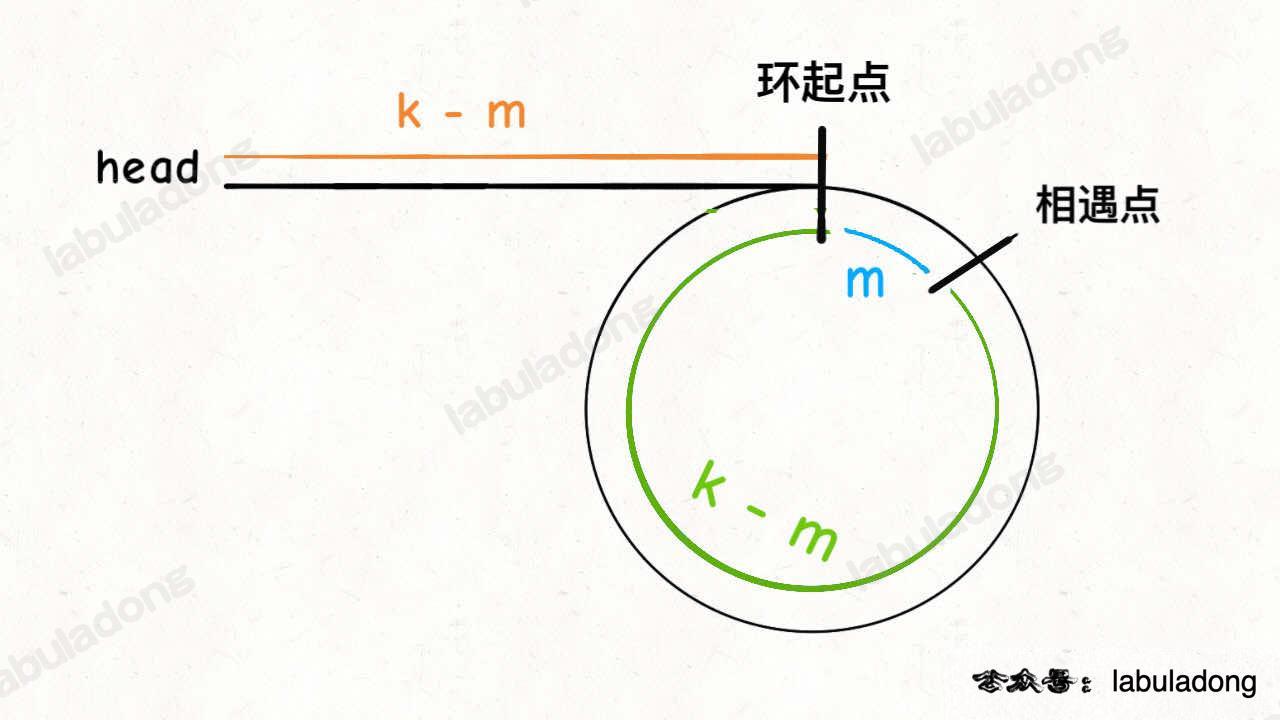
找到环的起点
使用上述双指针方法,知道快慢指针指向同一个位置。
再让一个指针回第一个节点,两个指针同步移动相同距离,
再次相遇位置即为环的起点
返回两链表相交点
p1 = [1,2,3,4]
拼接 p1+p2 和 p2+p1
此时两个链表同步遍历下去, 若遇到两者相同的节点,则它就是相交点
数组 差分
维护一个差分数组 diff[n] = arr[n] - arr[n-1]
主要适用场景是频繁对原始数组的某个区间 的元素进行增减 。
例如:在 [ i , j ] 之间 所有元素都加1
遍历
旋转矩阵
沿着主对角线对折后,再rever每行元素 = 顺时针旋转90°
螺旋遍历矩阵
用一个d 和 一个flag 辅助数组 遍历 , 空间复杂度O(m*n)
1 2 3 4 5 6 const d = { 0 : [0 , 1 ], 1 : [1 , 0 ], 2 : [0 , -1 ], 3 : [-1 , 0 ] }
空间复杂度O(1)
1 2 var upper_bound = 0 , lower_bound = m - 1 ;var left_bound = 0 , right_bound = n - 1 ;
T54 T54
滑动窗口 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 const window = new Map ()let left = 0 , right = 0 ;let valid = 0 ; while (left < right && right < s.length ) { window .set (s[right], window .get (s[right])?window .get (s[right])+1 : 1 ); right++; while (window needs shrink) { window .set (s[left], window .get (s[left])-1 ); left++; } }
二分搜索
防止溢出 (l+r)/2 === l + (r - l)/2
左侧边界优先二分搜索 不同的二分搜索对于 [1,2,2,2,3] return 2 而不是 1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 function left_bound_binary_search (nums, target) { let left = 0 , right = nums.length - 1 ; while (left <= right) { let mid = left + ((right - left) >> 1 ); if (nums[mid] == target){ right = mid - 1 ; } else if (nums[mid] < target) { left = mid + 1 ; } else if (nums[mid] > target) { right = mid - 1 ; } } if (left < 0 || left >= nums.length ) { return -1 ; } return nums[left] == target ? left : -1 ; };
右侧边界优先二分搜索 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 function right_bound_binary_search (nums, target) { let left = 0 , right = nums.length - 1 ; while (left <= right) { int mid = left + (right - left) >> 1 ; if (nums[mid] == target){ left = mid + 1 ; } else if (nums[mid] < target) { left = mid + 1 ; } else if (nums[mid] > target) { right = mid - 1 ; } } if (right < 0 || right >= nums.length ) { return -1 ; } return nums[right] == target ? right : -1 ; };
树 二叉搜索树
1 2 3 4 5 6 7 8 9 10 11 var BST = function (root, target ) { if (root.val === target) { } if (root.val < target) { BST (root.right , target); } if (root.val > target) { BST (root.left , target); } };
1 2 3 4 5 6 7 8 9 10 11 var insertIntoBST = function (root, val ) { if (root === null ) return new TreeNode (val); if (root.val < val) root.right = insertIntoBST (root.right , val); if (root.val > val) root.left = insertIntoBST (root.left , val); return root; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 var deleteNode = function (root, key ) { if (root == null ) return null ; if (root.val == key) { if (root.left == null ) return root.right ; if (root.right == null ) return root.left ; let minNode = getMin (root.right ); root.right = deleteNode (root.right , minNode.val ); minNode.left = root.left ; minNode.right = root.right ; root = minNode; } else if (root.val > key) { root.left = deleteNode (root.left , key); } else if (root.val < key) { root.right = deleteNode (root.right , key); } return root; } var getMin = function (node ) { while (node.left != null ) node = node.left ; return node; }
图 dfs遍历 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 var visited = [];var onPath = [];function traverse (graph, s ) { if (visited[s]) return ; visited[s] = true ; onPath[s] = true ; for (var i = 0 ; i < graph.neighbors (s).length ; i++) { var neighbor = graph.neighbors (s)[i]; traverse (graph, neighbor); } onPath[s] = false ; }
图的拓扑排序就是图的dfs后序排序再reverse
判断环 基于dfs,通过onPath.includes(cur)判断 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 var findOrder = function (numCourses, prerequisites ) { const visited = new Array (numCourses).fill (false ) const onPath = []; const graph = generateGraph (numCourses, prerequisites) let hasCircle = false ; for (let i = 0 ; i < numCourses; i++) { dfs (i) } return hasCircle function dfs (cur ) { if (onPath.includes (cur)) hasCircle = true ; if (visited[cur] || hasCircle) return ; visited[cur] = true ; onPath.push (cur) let p = graph[cur].next ; while (p) { dfs (p.val ); p = p.next ; } onPath.pop (); } };
基于拓扑排序 拓扑顺序count===num 拓扑排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 let indegree = new Array (numCourses).fill (0 );let graph = buildGraph2 (numCourses, prerequisites, indegree);let q = [];for (let i = 0 ; i < numCourses; i++) { if (indegree[i] == 0 ) { q.push (i); } } while (q.length > 0 ) { let cur = q.shift (); let p = graph[cur].next ; while (p) { indegree[p.val ]--; if (indegree[p.val ] === 0 ) { q.push (p.val ) } p = p.next ; } }
拓扑排序与dfs区别:使用indegree[]而不是visited[]
背包 0-1背包 要么装进包里,要么不装,不能说切成两块装一半
1 2 3 4 5 6 7 8 9 10 11 12 const dp[N+1 ][W+1 ]dp[0 ][..] = 0 dp[..][0 ] = 0 for i in [1. .N ]: for w in [1. .W ]: dp[i][w] = max ( 把物品 i 装进背包, 不把物品 i 装进背包 ) return dp[N][W]
完全背包 一个物品可以装进无限次,也可以不装
处理循环数组
下标取余
复制一份再首尾连接起来
LRU 最近最旧未使用